Obsah článku
Hledání mezer v obsahu? V čem mi to pomůže?Jak na Contant GAP analýzu
- Potřebné nástroje
- Jak zjistit konkurenci
- Ideální počet konkurentů
- Kde hledat data pro obsahovou analýzu?
Content gap analýza je technika, která může být aplikována samostatně, nebo také jako součást celého strategického auditu konkurence, či komplexní konkurenční analýzy. Zároveň se může jednat o analýzu celých konkurenčních webů, nebo pouze jejich konkrétních částí, či dokonce jednotlivých tematických stránek, které máme a chceme vylepšit. Z tohoto pohledu tedy můžeme někdy mluvit také o Keyword GAP analýze.
Hledání mezer v obsahu? V čem mi to pomůže?
Content GAP technika vám může pomoci objevit mezery v obsahu, či potenciál k jeho rozvoji. Záleží, zda ji aplikujete na již existující, nebo teprve vznikající web. Prvně zmiňovaná varianta je obvyklejší. Jednak proto, že u nově vznikajícího webu je většinou prioritou, alespoň by mělo být, zpracování analýzy klíčových slov, která je již sama o sobě značně časově náročná. To však neznamená, že by content GAP analýza nemohla být v určitém rozsahu alespoň její součástí. Například když se při sběru vstupních frází pro klíčovku inspirujeme u konkurence. Zároveň je její využití pro již existující web obvyklejší proto, že můžeme přesněji identifikovat:
- Jaký obsah máme a jak jej pokrýváme?
- Kdo jsou naši konkurenti?
- Na jakých pozicích se vyskytujeme ve výsledcích vyhledávání?
- Zjistit, kde jsme silní a porážíme konkurenci, či ji vůbec nemáme.
- Zjistit, kde jsme průměrní a víceméně vyrovnaně soutěžíme s konkurencí.
- Odhalit slabá místa, kde nekonkurujeme, ale mohli bychom.
Logicky pak následuje snaha posouvat odpovídající části obsahu umístěné na stupnici směrem vzhůru, tedy z bodu 3 do bodu 2, z dvojky do jedničky a ideálně umísťovaný obsah z bodu 1 pak monitorovat a udržovat. Zejména odhalení a pokrytí dosud chybějícího obsahu z 3. bodu je tzv. low-hanging fruit – nízko položené ovoce, kterým lze poměrně rychle dosáhnout zajímavých výsledků a je často primární motivací k provedení Content gap analýzy.
Jak na Contant GAP analýzu
Potřebné nástroje
Content GAP analýza je poměrně náročným procesem, proto se nelze obejít bez určité sady nástrojů. Nezbytnou samozřejmostí je nějaký tabulkový procesor. U nás využíváme Google Sheets díky snadné možnosti sdílení, ale stejně dobře poslouží i klasický Excel, LibreOffice Calc, či jiné alternativy. Tabulkové procesory mohou posloužit jednak k provedení některých operací v průběhu vytváření GAP analýzy, ale především se jedná o výstupní nástroj, ve kterém lze hotový dataset snadno prezentovat a dále s ním pracovat. Doporučuji na pomoc přibrat také Open Refine. Tento mocný nástroj pro velké sady dat může řadu operací usnadnit i urychlit. Jeho použití není nezbytné, ale budeme s ním při vysvětlování našeho konkrétního postupu počítat.
Dosavadní výčet byl k dostání zdarma, nyní se však bohužel neobejdeme bez některých placených nástrojů. Doporučit můžeme nástroje Marketing Miner a Ahrefs, které nám pomohou při výběru konkurentů a samozřejmě při extrakci dat. S ní nám může pomoci též Collabim a zároveň jej využijeme v závěrečné fázi pro monitoring a vyhodnocení efektivity vyselektovaných a nasazených klíčových frází. Volba nástroje samozřejmě záleží také na omezení, které se týkají jednotlivých tarifů.
Kromě výše uvedených nástrojů by bylo hříchem se nezmínit též o existenci šablon pro provedení Content GAP analýzy. Při troše googlení jistě na nějaké narazíte. My osobně máme zkušenost se šablonou od Filipa Podstavce a Marketing Mineru.

Zároveň jsme také testovali šablonu, na níž v povedném článku odkazuje Visibility.
Nespornou výhodou těchto předpřipravených šablon je jednoduchá použitelnost. Zkrátka jen extrahujete potřebná data, nahrajete je do šablony a ona vám vyplivne již přednastavené metriky. Šablona od Marketing Mineru má dokonce předpřipravené vizualizace. Při testování použitelnosti těchto šablon jsme však zároveň narazili na několik úskalí. Šablona od Marketing Mineru například moc neumožňuje pracovat s exporty dat z jiných nástrojů, a tak jsme odkázání pouze na jediný zdroj. Především jsou obě šablony založeny na Google tabulkách. Jejich zásadní nevýhodou je tak obecně pomalost a nespolehlivost při zpracovávání většího souboru dat. Pokud srovnáváte větší počet konkurentů, nebo se jedná o velké weby s velkým množstvím klíčových slov, může vás Google Sheets snadno zradit. Při použití proto připravte svoje nervy na dlouhé čekání, prodlevy, kdy nevíte, jestli se vůbec něco děje, a padající aplikace. Z tohoto důvodu jsme se v tomto článku rozhodli podrobně popsat vlastní postup, kterým spolehlivě zkrotíte i rozsáhlé Content GAP analýzy s velkými objemy dat. Ale abychom pouze nehaněli, šablony mají svoje využití. Pro menší analýzy nižších objemů dat se jedná o jednodušší a rychlejší cestu, jak dosáhnout požadovaného cíle, takže je určitě nezatracujte a vyzkoušejte si je na vlastní kůži. Třeba pro vás budou to pravé.
Jak zjistit konkurenci
Konkurence se dá samozřejmě hledat ručně, případně si vypomoci vyhledávacím operátorem „related:“. Spolehlivost operátoru je však kolísavá a googlení nám odhalí především konkurenty se silným brandem. Málo nám však poví o jejich obsahové spřízněnosti s analyzovaným webem. Již v prvopočátku se tedy jen obtížně obejdeme bez některých placených nástrojů. Ruční výsledky doporučujeme porovnat s návrhy nástroje Marketing Miner, který dokáže analyzovat celou doménu a návdavkem přidá i návrh až 5 tématicky nejbližších konkurentů na základě organického pokrytí.
Ještě lepší je v tomto ohledu Ahrefs, který jednak poskytuje v závislosti na tarifu více návrhů, také nám blahosklonně dodá i konkrétní data o obsahové podobnosti.

Nejsměrodatnějším údajem je v tomto ohledu asi procentuální vyjádření podobnosti pomocí sloupce „Common keywords, %“, podle kterého je report i primárně řazen. Je však možné seřadit výsledky i dle sloupců „Keywords unique to competitor“ nebo „Common keywords“, a obohatit tak seznam konkurenčních webů. Další výhodou Ahrefs je, že interně obsahuje nástroj pro provedení Content GAP analýzy.
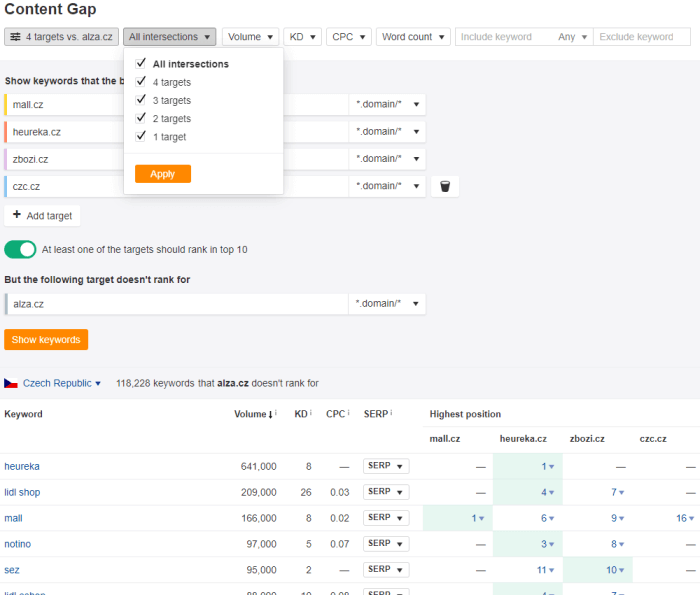
Stačí zadat analyzovanou doménu, požadovaný počet konkurenčních domén a poté už jen nastavit pravidlo pro zobrazení klíčových slov ve výpisu, tzn. u kolika konkurentů by mělo být klíčové slovo přítomno. Nevýhodou je, že poskytnutá data jsou opět silně limitována tarifem a s účtem Lite zobrazujícím pouze 10 výsledků je nástroj pro porovnání domén takřka nepoužitelný. Nehledě na to, že spoléhat pouze na jediný nástroj jako zdroj klíčových slov k analýze není nejjistější, ale k tomuto tématu se ještě dostaneme. Přesto není radno nástroj zatracovat. Kromě domén totiž dokáže porovnávat také obsah jednotlivých stránek a na této úrovni se dá teoreticky pracovat i s nižšími tarify.
Ideální počet konkurentů
A kolik že by vlastně ta Content GAP analýza měla zahrnovat konkurentů? V zásadě platí, čím více, tím lépe. Existuje zde však limitace s ohledem na to, co lze ještě považovat za tematicky podobný web a co je pouze dílčí obsahový překryv. Například téměř vždy budete mít v případě e-shopu množství společného obsahu s Heurékou, Mallem, Amazonem, či jinými giganty s širokým záběrem. Opravdu vám ale stojí za to, probírat se množstvím přidaného nerelevantního balastu, který s sebou tito hráči chtě nechtě přináší? Je nutno brát v úvahu efektivitu vzhledem k vynaloženým zdrojům, především tedy času, který narůstá úměrně s počtem analyzovaných konkurentů. Ideální je proto orientovat se podle obsahové příbuznosti vyjádřené procentuálně, protože jasně ukazuje, jak je konkurent podobný analyzovanému webu a přibližně s jakým množstvím relevantního obsahu lze počítat. Obecně se lze řídit tím, že relevantní konkurent by měl mít 10+ % společného obsahu. Tato hranice může značně kolísat v závislosti na segmentu, kterým se web zabývá.
Rozhodně jednodušší je určit, kolik konkurentů by analýza měla zahrnovat minimálně. V tomto případě je odpovědí alespoň 3 konkurenti + analyzovaný web. Úkolem Content GAP analýzy totiž není odhalit obsah a klíčová slova, na které se zobrazuje jeden konkurenční web a náš ne, ale ty, na které se zobrazují 2+ konkurentů, protože tím je verifikována důležitost obsahu, který nám uniká.
Kde hledat data pro obsahovou analýzu?
Kromě zjištění konkurence dokážou zmiňované placené nástroje výrazně pomoci také při dalším nezbytném kroku – sběru dat. Tedy při extrakci klíčových slov, které analyzované weby obsahují. Zde lze využít také další z placených nástrojů Collabim, konkrétně jednu z jeho jednorázových analýz – Svatý grál.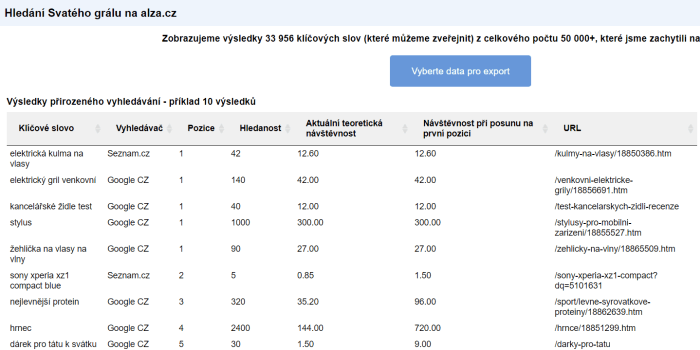
Cílem je přitom získat nejen množinu klíčových slov, které weby obsahují, ale ideálně i jejich hledanost a především pozice, na které se konkrétní analyzovaný web vyskytuje ve výsledcích vyhledávání. Tato data ke klíčovým slovům poskytují všechny ze jmenovaných nástrojů. Díky tomu můžeme již během tohoto kroku provést filtraci a omezit množství zpracovávaných dat již na vstupu. To se hodí zejména při analýze většího množství konkurentů.
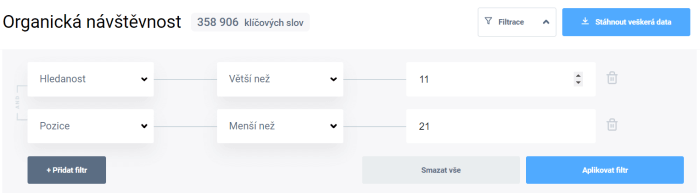
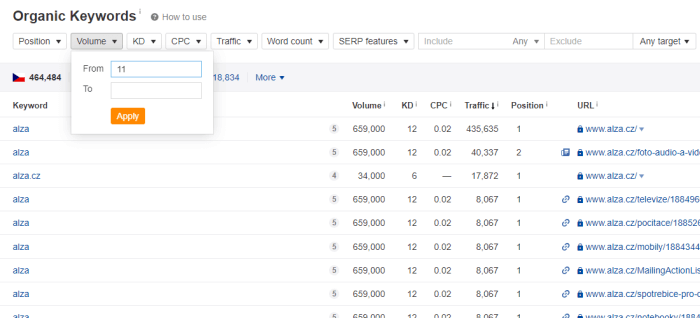
Pracujeme s daty
Odstranění duplicit
Data můžeme též rovnou očistit od duplicit, které způsobil zejména sběr ze dvou nezávislých zdrojů, a to buď funkcí přímo v Excelu, nebo případně v Open Refine. Čištění pomocí Open Refine doporučujeme z toho důvodu, že všechny datové listy do něj budeme stejně muset pro další operace nahrávat. Netřeba se při čištění příliš děsit toho, že se data o pozicích a hledanosti z různých zdrojů mohou lišit. Každý z nástrojů má zkrátka vlastní algoritmy pro scrapování dat, které se více či méně liší, takže 100% shoda je nereálná. Nám stačí že se data shodují přibližně. Případně lze při čištění vždy preferovat jeden z nástrojů a nalezené duplicity prioritně mazat u ostatních. K tomu lze využít abecední řazení. V Excelu tím způsobem, že první budou vypsána veškerá klíčová slova preferovaného nástroje. V Open Refine je zase důležité, aby se v případě abecedního řazení klíčových slov fráze s daty preferovaného nástroje nacházely v pořadí duplicit jako první.
Až si takto připravíme očištěné datové listy ke všem analyzovaným webům, je na čase založit sloučený seznam veškerých klíčových slov. Bude se v podstatě jednat jen o další list, do kterého sloučíme pouze extrahovaná klíčová slova ze všech analyzovaných webů bez dalších dat. Ten opět, stejným postupem jako v předchozích případech, očistíme od duplicit.
Čištění dat
Pokud jste tak neučinili už dříve, je nyní čas stáhnout jednotlivé listy tabulky ve formátu CSV a nahrát je odděleně do Open Refine, další operace budou totiž prováděny v tomto nástroji. Nyní využijeme funkci „Add column(s) from other projects“ u datasetu obsahující klíčová slova ze všech analyzovaných webů.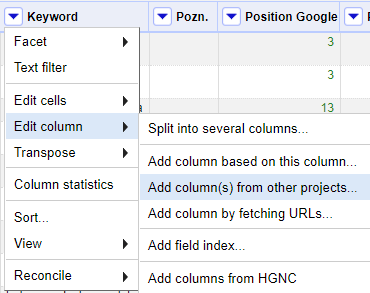
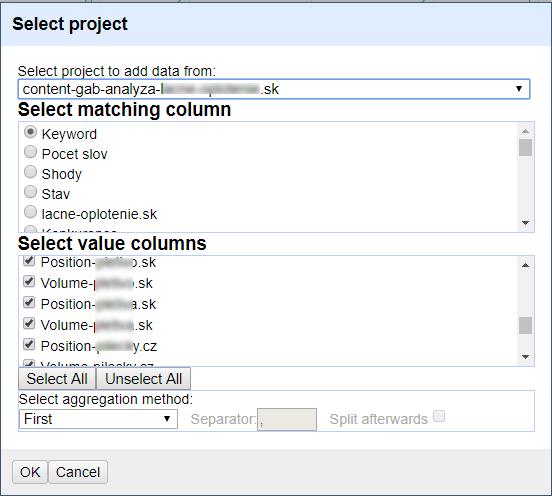
V současné fázi bychom zde zatím měli mít pouze jediný sloupec s klíčovými slovy, nad kterým lze operaci provést. Cílem bude importovat do souboru data o pozicích, případně i hledanosti klíčových slov z jednotlivých analyzovaných webů. Pro import je důležité správné pojmenování sloupců. Jednak potřebujeme, aby sloupec s klíčovými slovy byl napříč všemi datasety pojmenován stejně a my jej mohli použít jako spojovatele. Naopak je žádoucí, aby se data o pozicích klíčových slov u každého webu importovala zvlášť do vlastního unikátně pojmenovaného sloupce. V opačném případě bychom si totiž dokola přepisovali údaje o pozicích.
Požadovaným výstupem by tak měl být dataset obsahující množinu klíčových slov ze všech analyzovaných webů a k nim údaje o pozicích, na kterých se tyto weby umísťují. Při importu můžeme přidat též informace o hledanosti. Ty už však netřeba vkládat zvlášť do sloupců pro každý analyzovaný web, protože na rozdíl od pozic lze předpokládat, že hledanost je konzistentní nezávislý údaj, jehož opakovaný přepis ničemu nevadí.

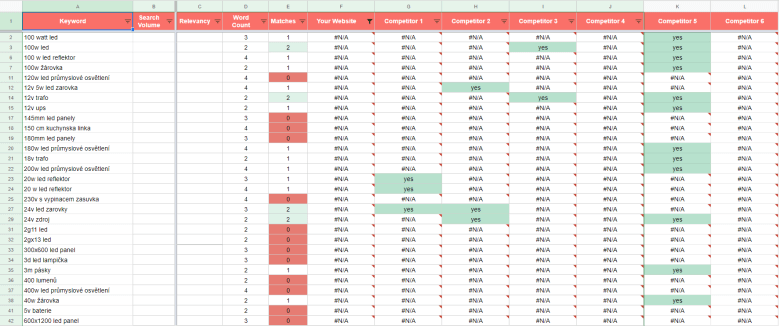
Nyní si v připraveném souboru dat vyfiltrujeme ta klíčová slova, na které se zobrazuje náš web. Použijeme k tomu textový facet nad sloupce s pozicemi našeho webu a zaškrtneme všechny hodnoty kromě „blank“. Pokud jsme při exportu dat z nástrojů použili již nějaký filtr ohledně pozic a hledanosti, můžeme si tato klíčová slova poznačit do zvláště vytvořeného sloupce a dále se jimi nezabývat. Jedná se totiž o fráze, které již pokrýváme. Pokud však při exportu nebyl žádný filtr aplikován, je vhodné jej použít nyní a odfiltrovat málo hledané fráze, či takové, na které se náš web již zobrazuje na dobrých pozicích.
V rámci dalšího čištění datasetu odfiltrujeme ta klíčová slova, na které se umisťuje pouze jediný z analyzovaných konkurenčních webů. K tomu nám v Open Refine opět poslouží textové facety použité nad sloupci s pozicemi jednotlivých konkurentů. Postupně si u všech sloupců zaškrtneme volbu „blank“, dokud u posledního ze sloupců nezbydou pouze volby s hodnotami. Tím si vyfiltrujeme unikátní klíčová slova, která výhradně pokrývá pouze příslušný konkurenční web a zaznamenáme si je nejlépe v novém sloupci sloužícím pro záznam těchto unikátních klíčových slov jednotlivých webů. Operaci postupně aplikujeme na všechny konkurenční weby.
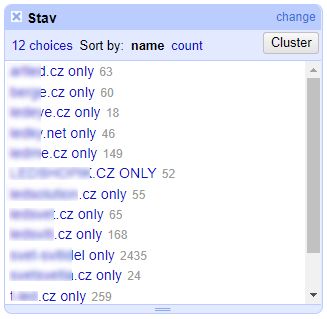
Tato slova pro nás nejsou primárně zajímavá, protože na ně reaguje pouze jeden z konkurenčních webů, a se vší pravděpodobností tak pro nás nejsou relevantní. Avšak je vhodné si je pro jistotu nechat stranou a projít později, pokud bude čas na podrobnější analýzu. Prozatím stačí, že jsme si je poznamenali a můžeme je snadno odfiltrovat.
Nyní bychom tedy měli být schopni snadno v datasetu zobrazit pouze ta slova, na které se náš web zobrazuje špatně, či vůbec, a přitom na ně reaguje 2 a více konkurenčních webů. V této fázi lze zredukované fráze exportovat z Open Refine a pomocí placených nástrojů k nim zjistit pozice webu, přistávací stránky a i hledanost, pokud nebyla přenesena z předchozích kroků, či chceme konzistentní data z jednoho nástroje. Získaný dataset nahrajeme zpět do Open Refine a opět pomocí funkce „Add column(s) from other projects“ přidáme sloupce nově získaných dat k našemu hlavnímu souboru. Pomocí údajů o pozicích můžeme ověřit, zda náš web na daná klíčová slova alespoň nějak reaguje a jestli k němu vyhledávače evidují přistávací stránku. V tomto stavu již můžeme začít soubor procházet a identifikovat klíčová slova, která jsou pro náš web zajímavá.
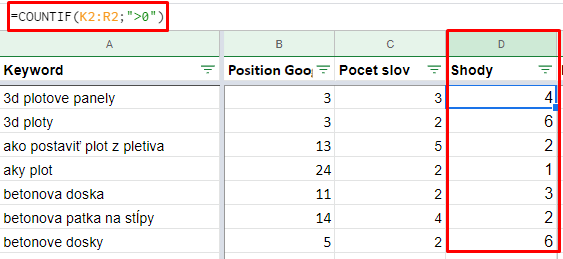
Segmentace dat
V mnoha případech by se stále mohlo jednat o rozsáhlý soubor klíčových slov v řádech stovek až dokonce tisíců. Proto je potřeba přemýšlet nad další redukcí datasetu. V dalším kroku tedy můžeme u všech klíčových slov zaznamenat, kolik konkurentů se na ně zobrazuje ve vyhledávání. K tomuto účelu můžeme buďto sloužit odpovídající dotaz v Open Refine, nebo použít v tabulkových procesorech funkci „COUNTIF“. Logicky nás pak budou primárně zajímat slova s nejvyšším počtem shod, protože čím více konkurentů na frázi reaguje, tím větší pravděpodobnost, že nám uniká relevantní obsah. Můžeme jít přitom ještě více do hloubky a pomocí téže funkce identifikovat pouze ty klíčové fráze, na které se jeden či více konkurentů objevují ve výsledcích vyhledávání v TOP 10 a výše.